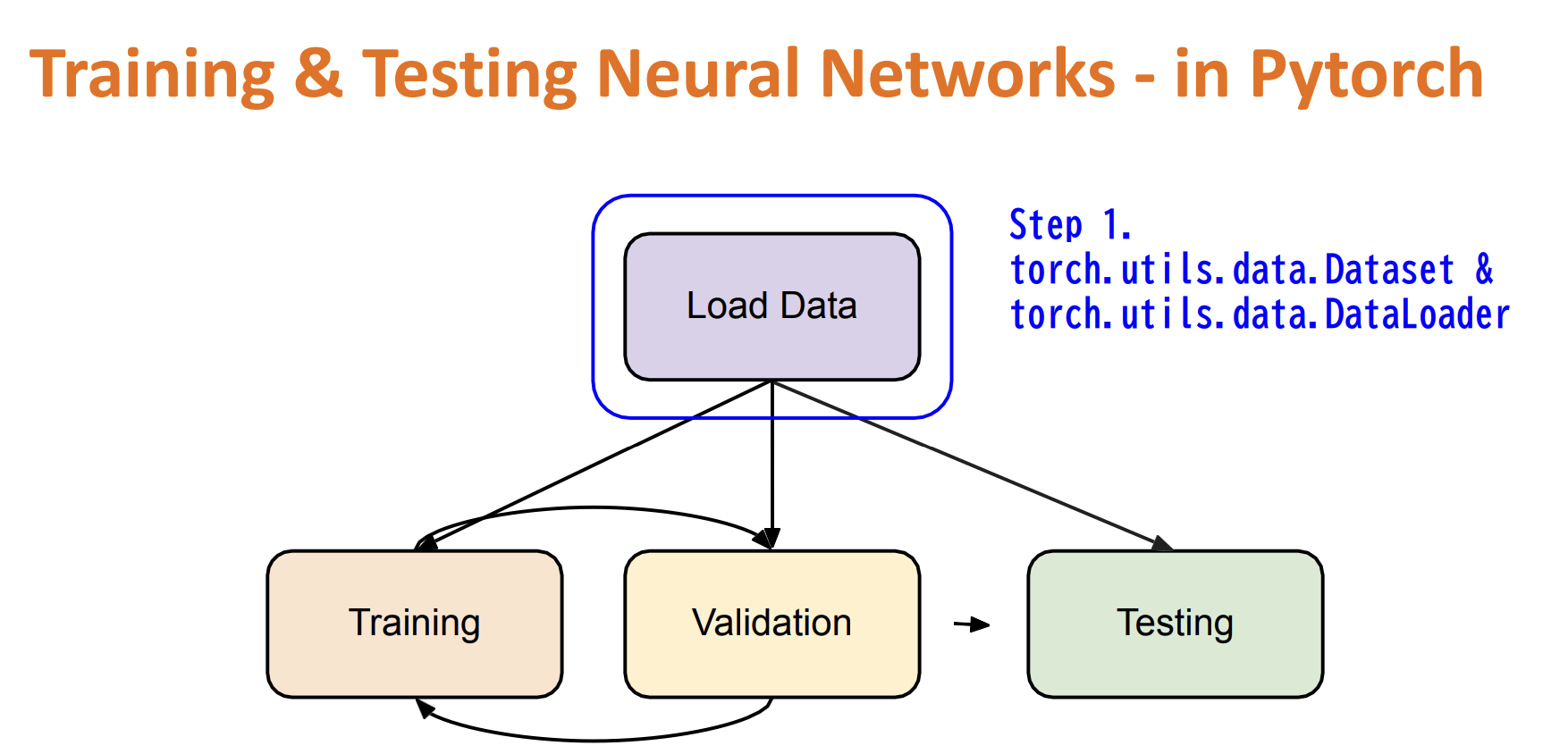
Training & Testing Neural Networks
Dataset & Dataloader
-
Dataset: stores data samples and expected values
-
Dataloader: groups data in batches, enables multiprocessing
dataset = MyDataset(file) dataloader = DataLoader(dataset, batch_size, shuffle=True) # Shuffle: Traning True, Testing False -
Design Own DataSet:
from torch.utils.data import Dataset, DataLoader class MyDataset(Dataset): def init (self, file): # Read data & preprocess self.data = ... def __getitem__(self, index): # Returns one sample at a time return self.data[index] def __len__(self): # Returns the size of the dataset return len(self.data)
Tensors
dimin PyTorch ==axisin NumPy- Creating:
x = torch.tensor([[1, -1], [-1, 1]])x = torch.from_numpy(np.array([[1, -1], [-1, 1]]))x = torch.zeros([2, 2]) #parameter is Shape object.x = torch.ones([1, 2, 5])
- Common Operations:
-
Addition:
z = x + y -
Subtraction:
z = x - y -
Summation:
y = x.sum() -
Mean:
y = x.mean() -
Power:
z = x.pow(y) -
Transpose: Transpose two specified dimensions.
x = torch.zeros([2, 3]) x.shape # torch.Size([2, 3]) x = x.transpose(0, 1) x.shape # torch.Size([3, 2]) -
Squeeze: remove the specified dimension with length = 1
x = torch.zeros([1, 2, 3]) x.shape # torch.Size([1, 2, 3]) x = x.squeeze(dim=0) x.shape # torch.Size([2, 3]) -
unsqueeze: expand a new dimension
x = torch.zeros([2, 3]) x.shape # torch.Size([2, 3]) x = x.squeeze(dim=1) x.shape # torch.Size([2, 3]) -
cat: concatenate multiple tensors
x = torch.zeros([2, 1, 3]) y = torch.zeros([2, 3, 3]) z = torch.zeros([2, 2, 3]) w = torch.cat([x, y, z], dim = 1) w.shape # torch.Size([2, 6, 3])
-
- Data Type: torch.Tensor — PyTorch 2.0 documentation
- 32-bit floating point →
torch.float→torch.FloatTensor - 64-bit integer point (signed) →
torch.long→torch.LongTensor
- 32-bit floating point →
- Comparision with NumPy: torch.Tensor — PyTorch 2.0 documentation
- Similar attributes:
shape, dtype - Similar functions:
reshape, squeeze, unsqueeze, viewx.unsqueeze(1)===np.expand_dims(x, 1)
- Similar attributes:
- Device
- Tensors & modules will be computed with CPU by default
- Use
.to('cpu' | 'cuda')to move tensors to appropriate devices. - Check if your computer has NVIDIA GPU:
torch.cuda.is_available() - Multiple GPUs: specify
cuda:0, cuda:1, cuda:2, ... - Why GPU: What is a GPU and do you need one in Deep Learning? | by Jason Dsouza | Towards Data Science
- Gradient Calculation

x = torch.tensor([[1., 0.], [-1., 1.]],requires_grad=True)z = x.pow(2).sum()z.backward()x.grad
Define Neural Network

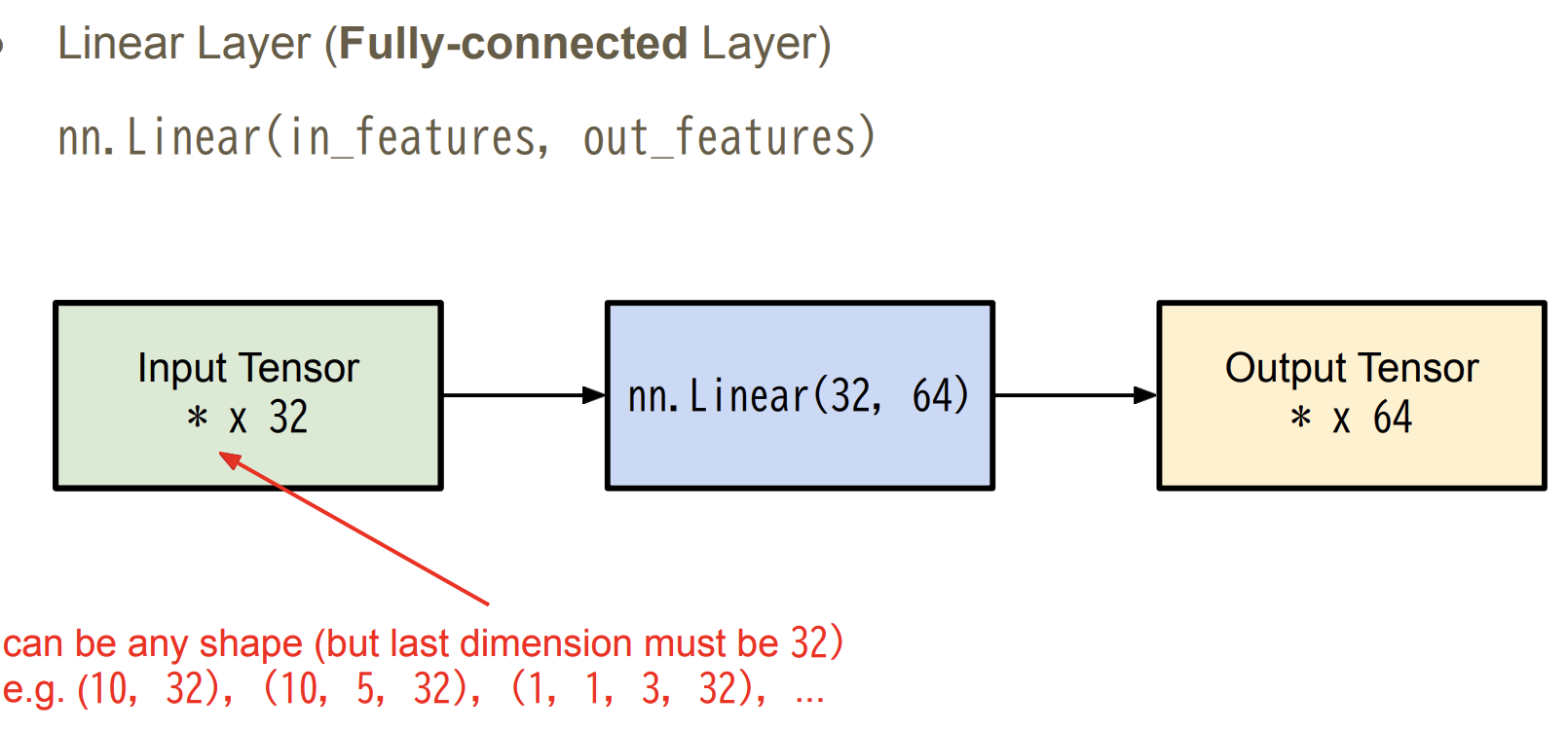

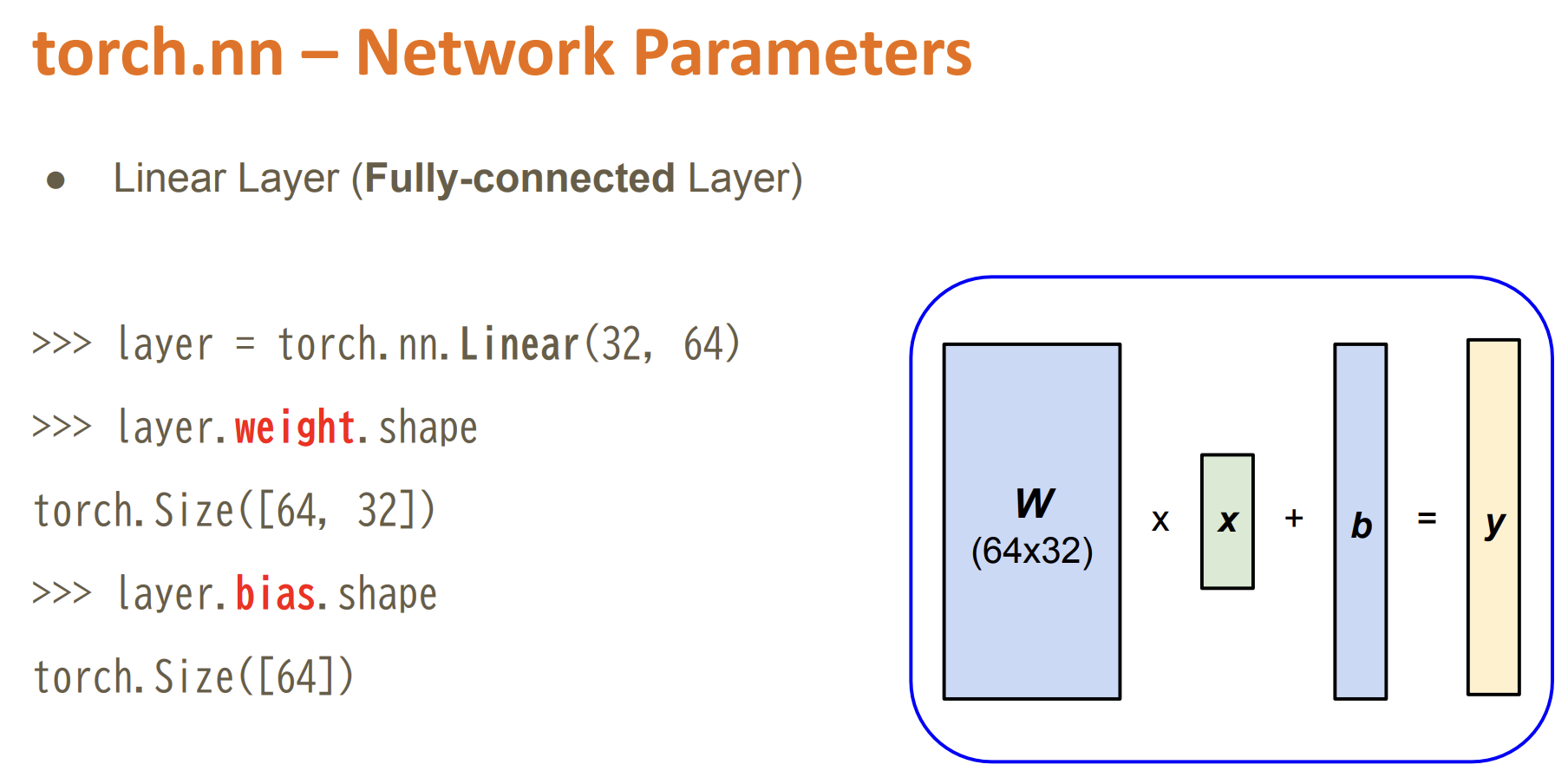
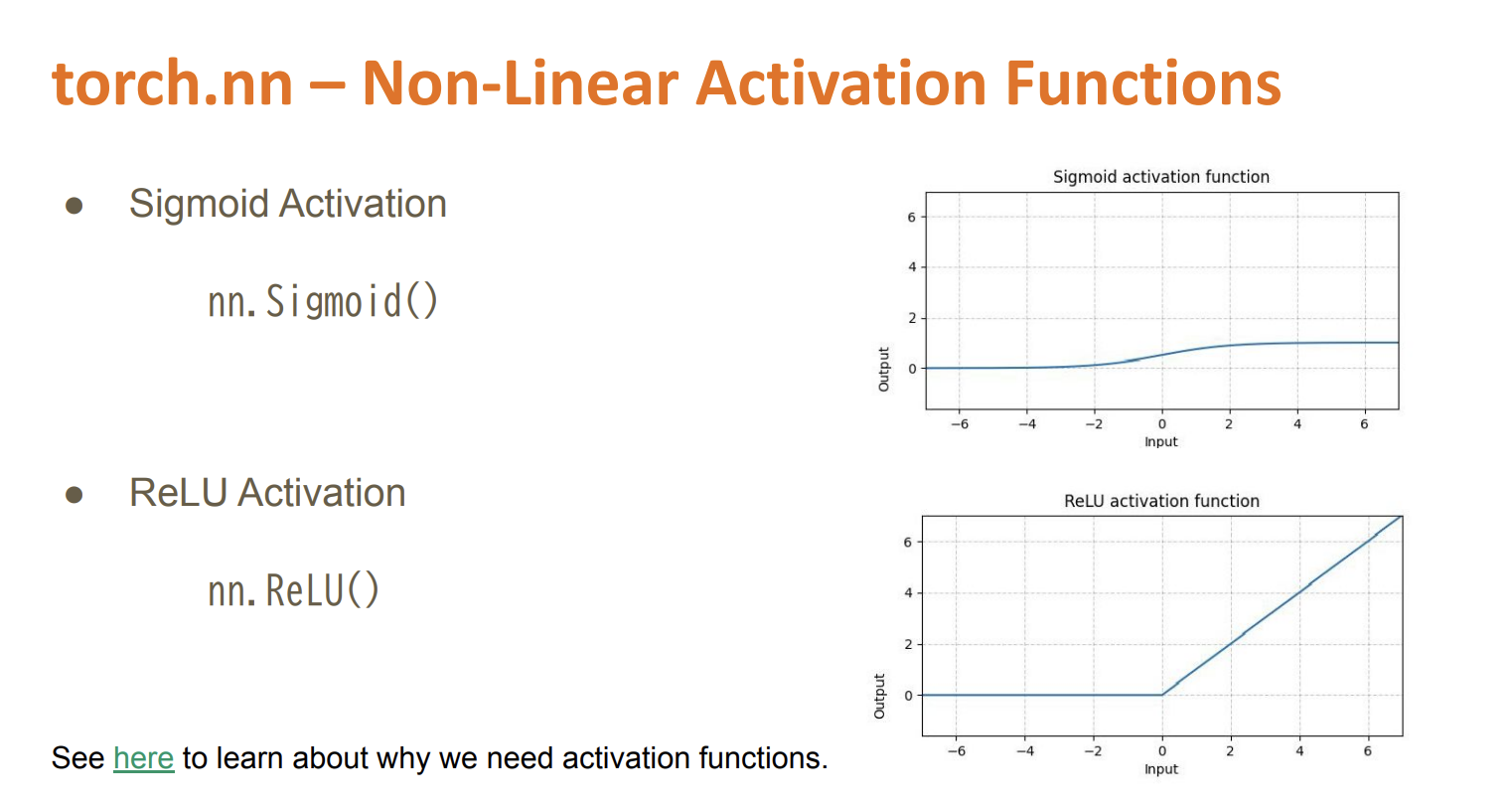
import torch.nn as nn
class MyModel(nn.Module):
def init(self): # Initialize your model & define layers
super(MyModel, self).init ()
self.net = nn.Sequential(
nn.Linear(10, 32),
nn.Sigmoid(),
nn.Linear(32, 1)
)
def forward(self, x): # Compute output of your NN
return self.net(x)
Loss Function

- Mean Squared Error (for regression tasks)
criterion = nn.MSELoss()
- Cross Entropy (for classification tasks)
criterion = nn.CrossEntropyLoss()
loss = criterion(model_output, expected_value)
Optimization

- Gradient-based optimization algorithms that adjust network parameters to reduce error. (See Adaptive Learning Rate lecture video)
- E.g. Stochastic Gradient Descent (SGD):
optimizer = torch.optim.SGD(model.parameters(), lr, momentum = 0) - For every batch of data
- Call
optimizer.zero_grad()to reset gradients of model parameters. - Call
loss.backward()to backpropagate gradients of prediction loss. - Call
optimizer.step()to adjust model parameters.
- Call
Workflow

Training Setup
dataset = MyDataset(file) # read data via MyDataset
tr_set = DataLoader(dataset, 16, shuffle=True) # put dataset into Dataloader
model = MyModel().to(device) # construct model and move to device (cpu/cuda)
criterion = nn.MSELoss() # set loss function
optimizer = torch.optim.SGD(model.parameters(), 0.1) # set optimizerTraining Loop
for epoch in range(n_epochs): # iterate n_epochs
model.train() # set model to train mode
for x, y in tr_set: # iterate through the dataloader
optimizer.zero_grad() # set gradient to zero
x, y = x.to(device), y.to(device) # move data to device (cpu/cuda)
pred = model(x) # forward pass (compute output)
loss = criterion(pred, y) # compute loss
loss.backward() # compute gradient (backpropagation)
optimizer.step() # update model with optimizerValidation Loop
model.eval() # set model to evaluation mode
total_loss = 0
for x, y in dv_set: # iterate through the dataloader
x, y = x.to(device), y.to(device) # move data to device (cpu/cuda)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass (compute output)
loss = criterion(pred, y) # compute loss
total_loss += loss.cpu().item() * len(x) # accumulate loss
avg_loss = total_loss / len(dv_set.dataset) # compute averaged lossTesting Loop
model.eval() # set model to evaluation mode
preds = []
for x in tt_set: # iterate through the dataloader
x = x.to(device) # move data to device (cpu/cuda)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass (compute output)
preds.append(pred.cpu()) # collect predictionmodel.eval()Changes behaviour of some model layers, such as dropout and batch normalization.
with torch.no_grad()Prevents calculations from being added into gradient computation graph. Usually used to prevent accidental training on validation/testing data.
Save/Load Trained Models
- Save
torch.save(model.state_dict(), path) - Load
ckpt = torch.load(path)
model.load_state_dict(ckpt)More About PyTorch
torchaudio
speech/audio processing
torchtext
natural language processing
torchvision
computer vision
skorch
scikit-learn + pyTorch
Useful github repositories using PyTorch
○ Huggingface Transformers (transformer models: BERT, GPT, …) ○ Fairseq (sequence modeling for NLP & speech) ○ ESPnet (speech recognition, translation, synthesis, …)