Tunning your leaning rates

Adaptive Learning Rates
-
Popular & Simple Idea: Reduce the learning rate by some factor every few epochs.
- At the beginning, we are far from the destination, so we use larger learning rate
- After several epochs, we are close to the destination, so we reduce the learning rate
- E.g. 1/t decay: .
-
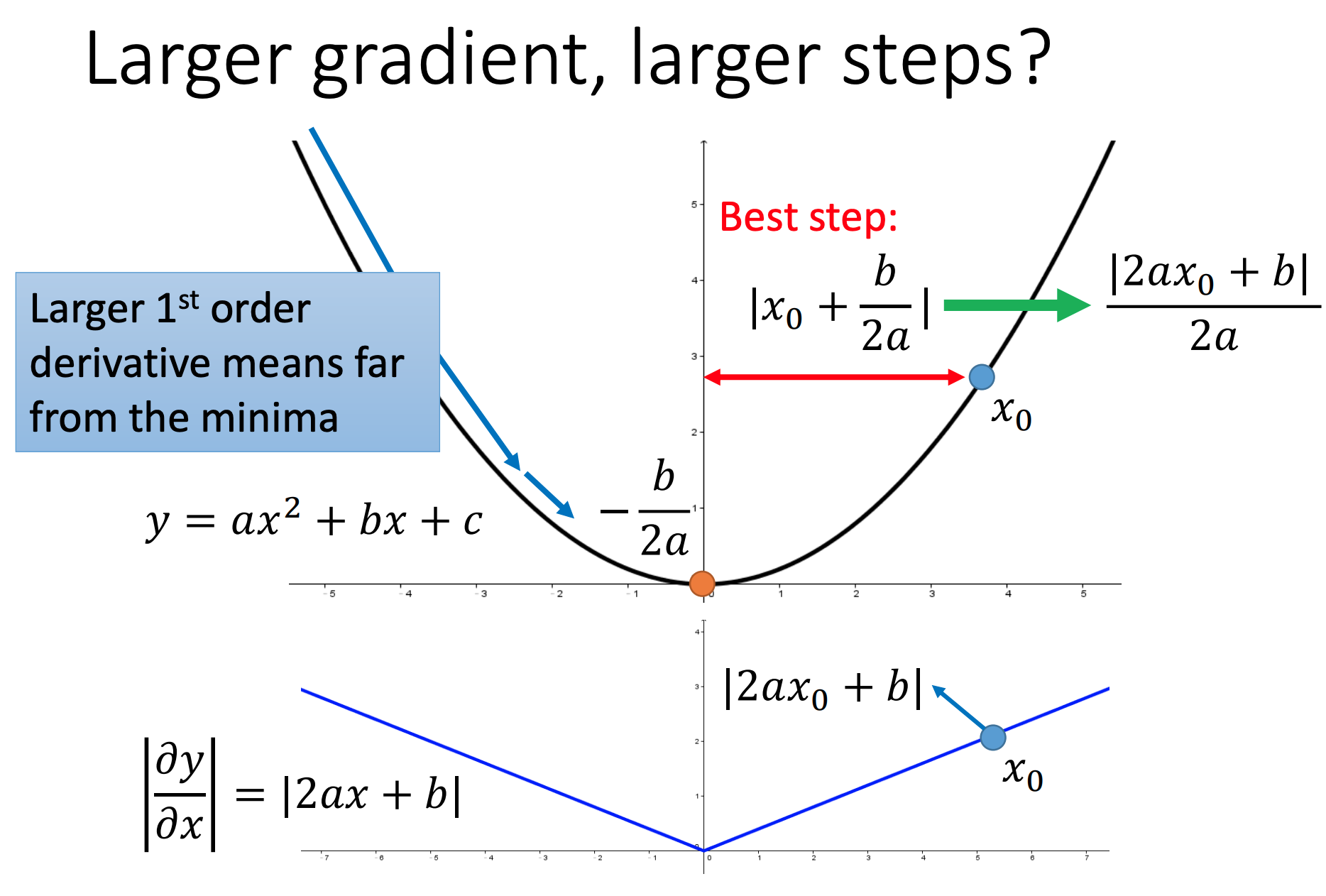
Learning rate cannot be one-size-fits-all
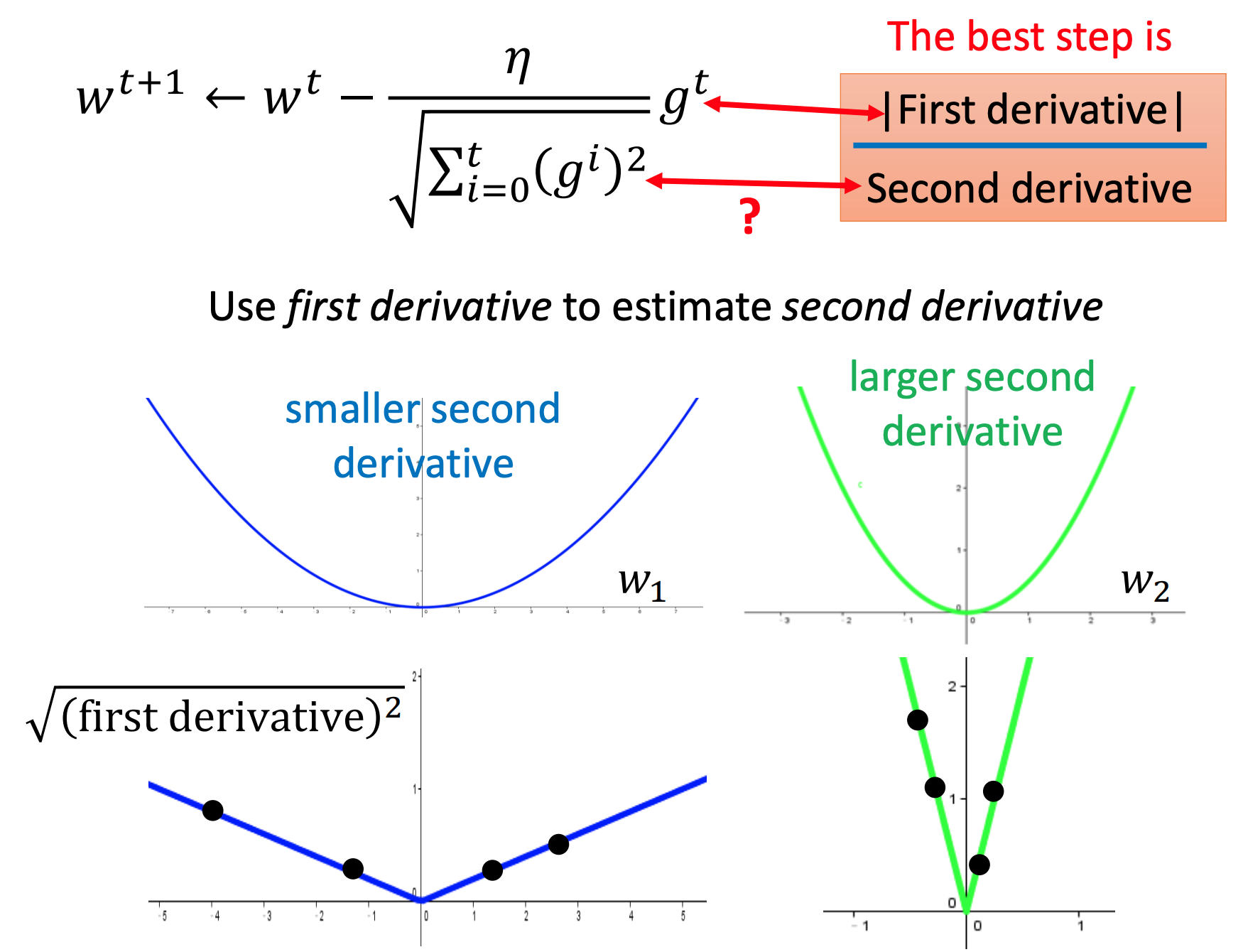
Adagrad








Stochastic Gradient Descent
Feature Scaling
Others
-
RMSprop(Root Mean Square Propagation):RMSprop是一种自适应学习率算法,它对AdaGrad进行了改进。RMSprop通过维护梯度平方的移动平均来调整学习率,以便在训练过程中更好地适应不同参数的更新频率。
-
Adadelta:Adadelta也是一种自适应学习率算法,它对RMSprop进行了改进。Adadelta通过考虑梯度的移动平均和参数更新的移动平均来动态地调整学习率。与其他算法不同,Adadelta不需要设置全局学习率。
-
Adamax:Adamax是对Adam算法的改进,主要针对在很大规模训练中对内存消耗较大的问题。Adamax使用了一种更简单的无界范数来替代Adam中的L2范数,从而减少了内存需求。
-
Nadam:Nadam是对Adam算法的改进,结合了Nesterov动量和Adam的特性。Nadam通过引入Nesterov动量的修正项来加速收敛,并且具有Adam的自适应学习率特性。
-
AMSGrad:AMSGrad是对Adam算法的改进,旨在解决Adam无法收敛到局部最小值的问题。AMSGrad通过维护梯度的历史最大值来修正Adam中的梯度平方的移动平均,从而保证梯度平方的估计不被过分抑制。
这些算法都是对传统梯度下降算法的改进,旨在提高深度学习模型的收敛速度和性能。每个算法都有其独特的特点和适用范围,选择合适的算法通常需要根据具体问题进行实验和调优。
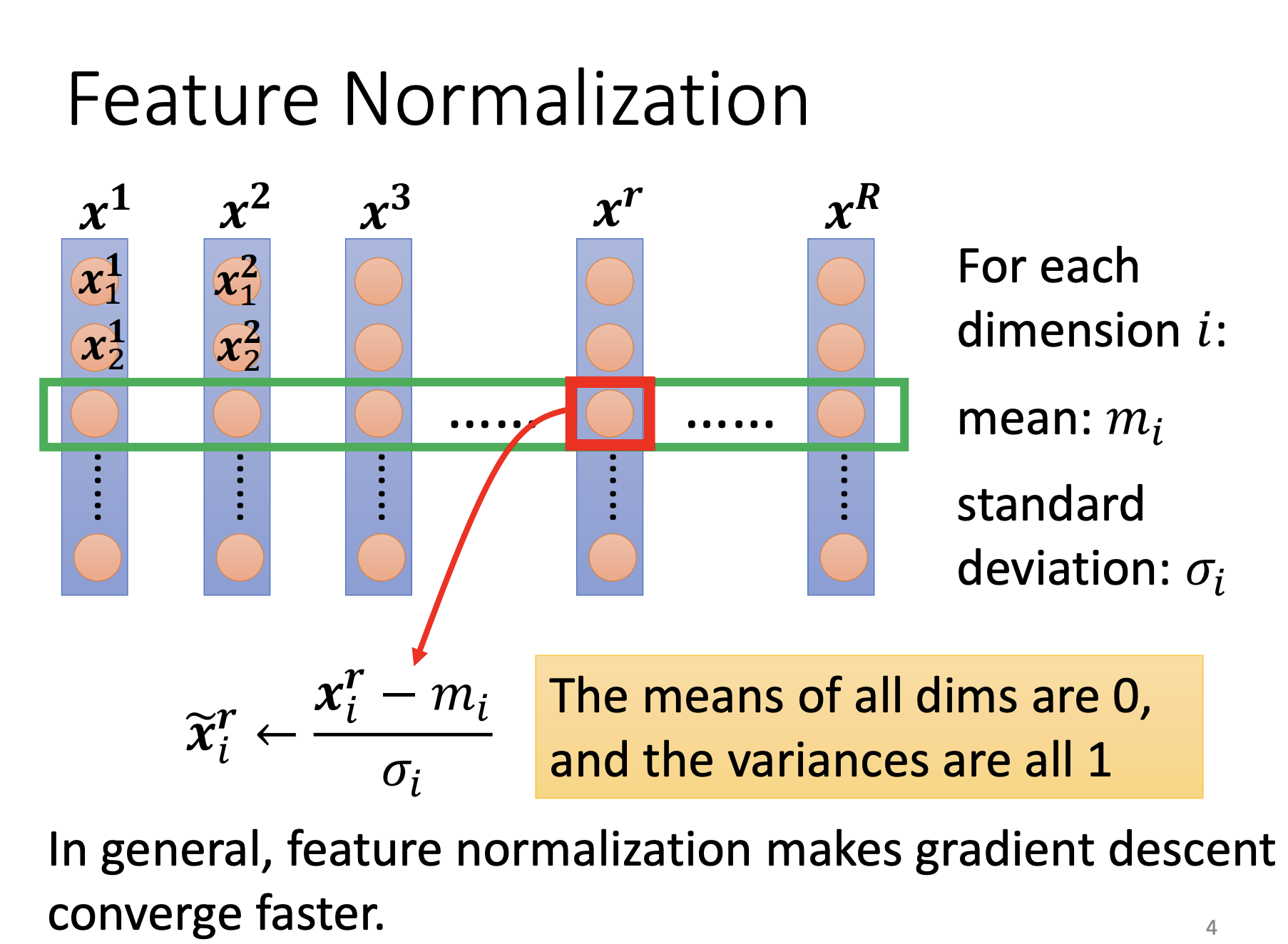
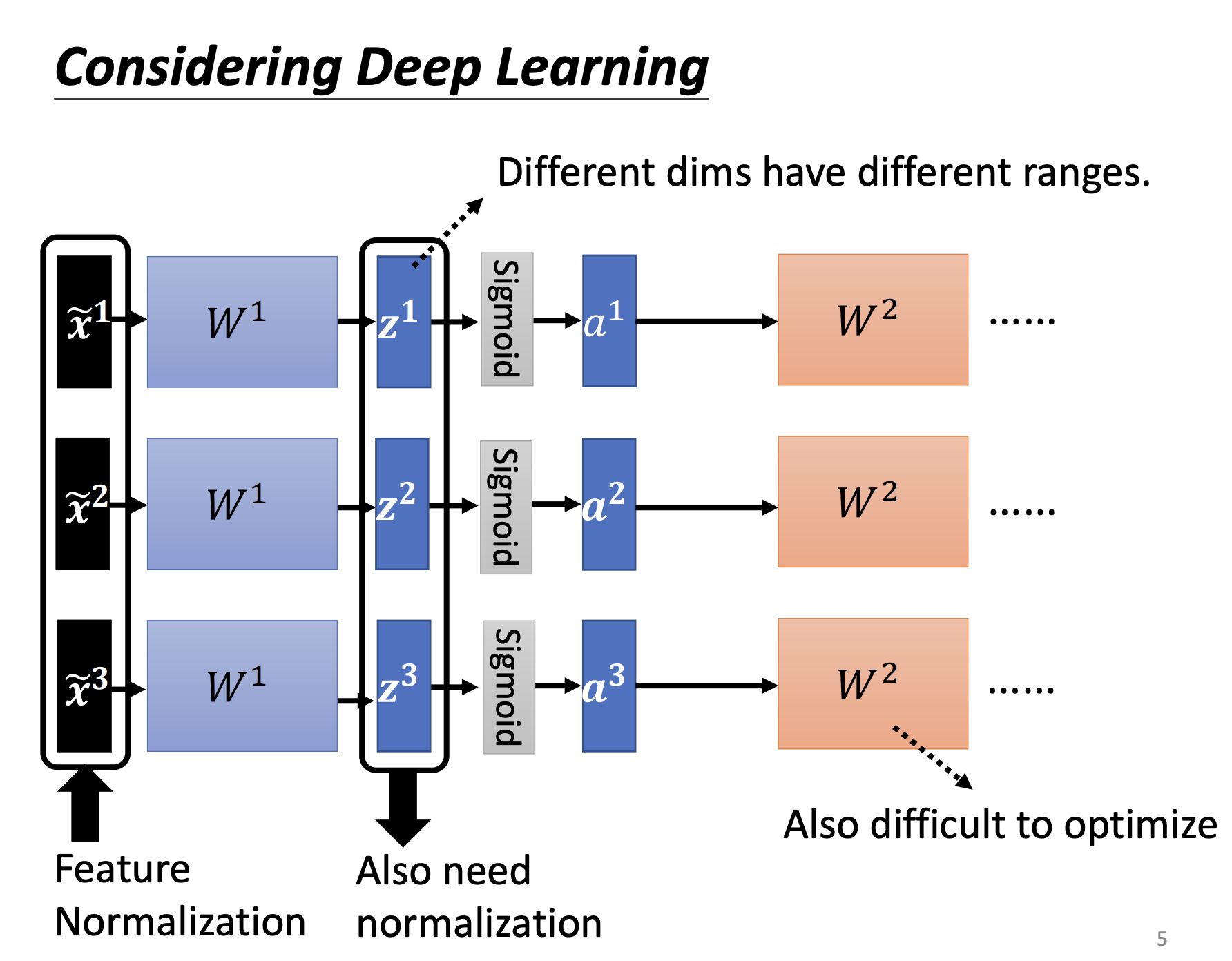
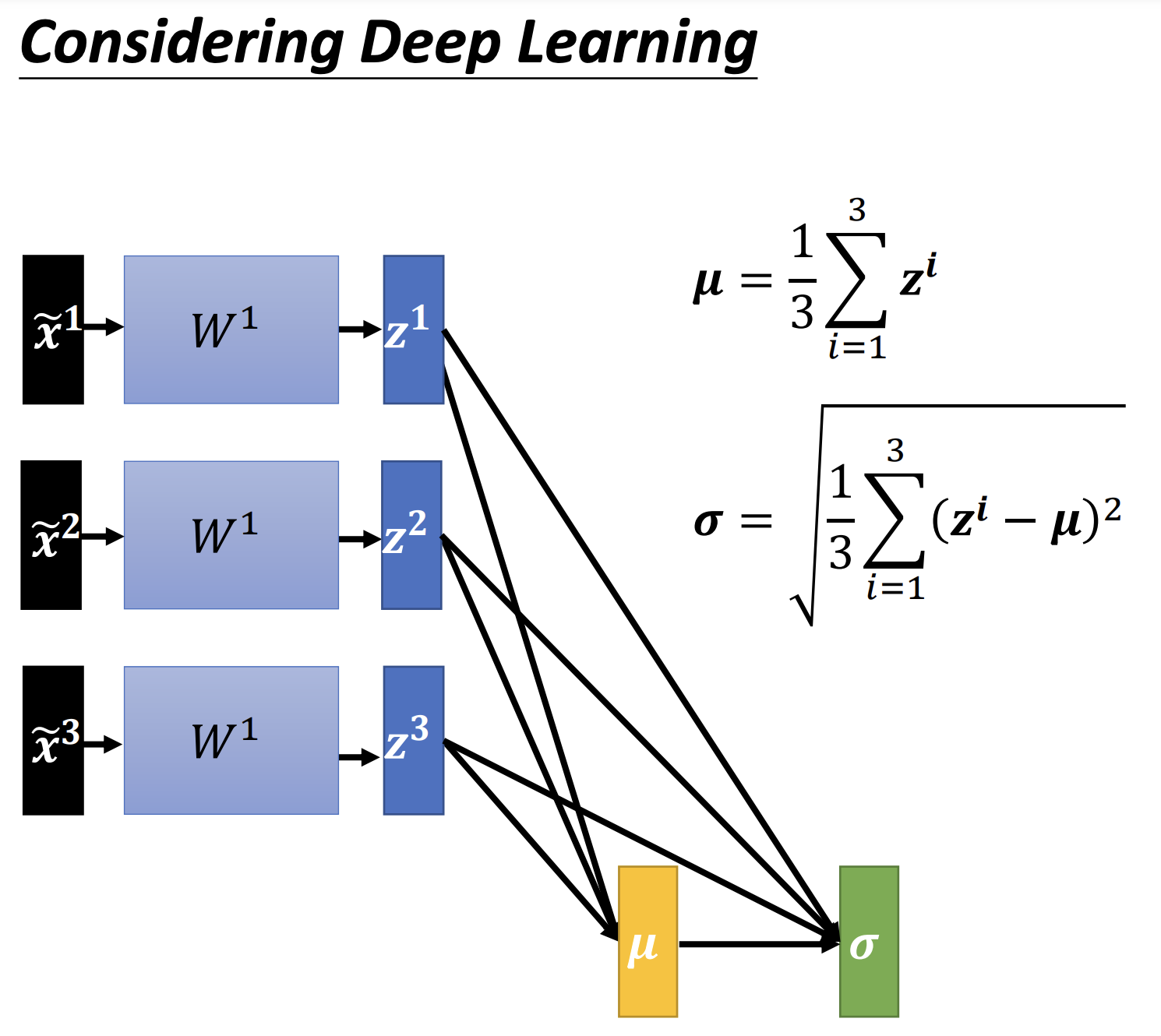
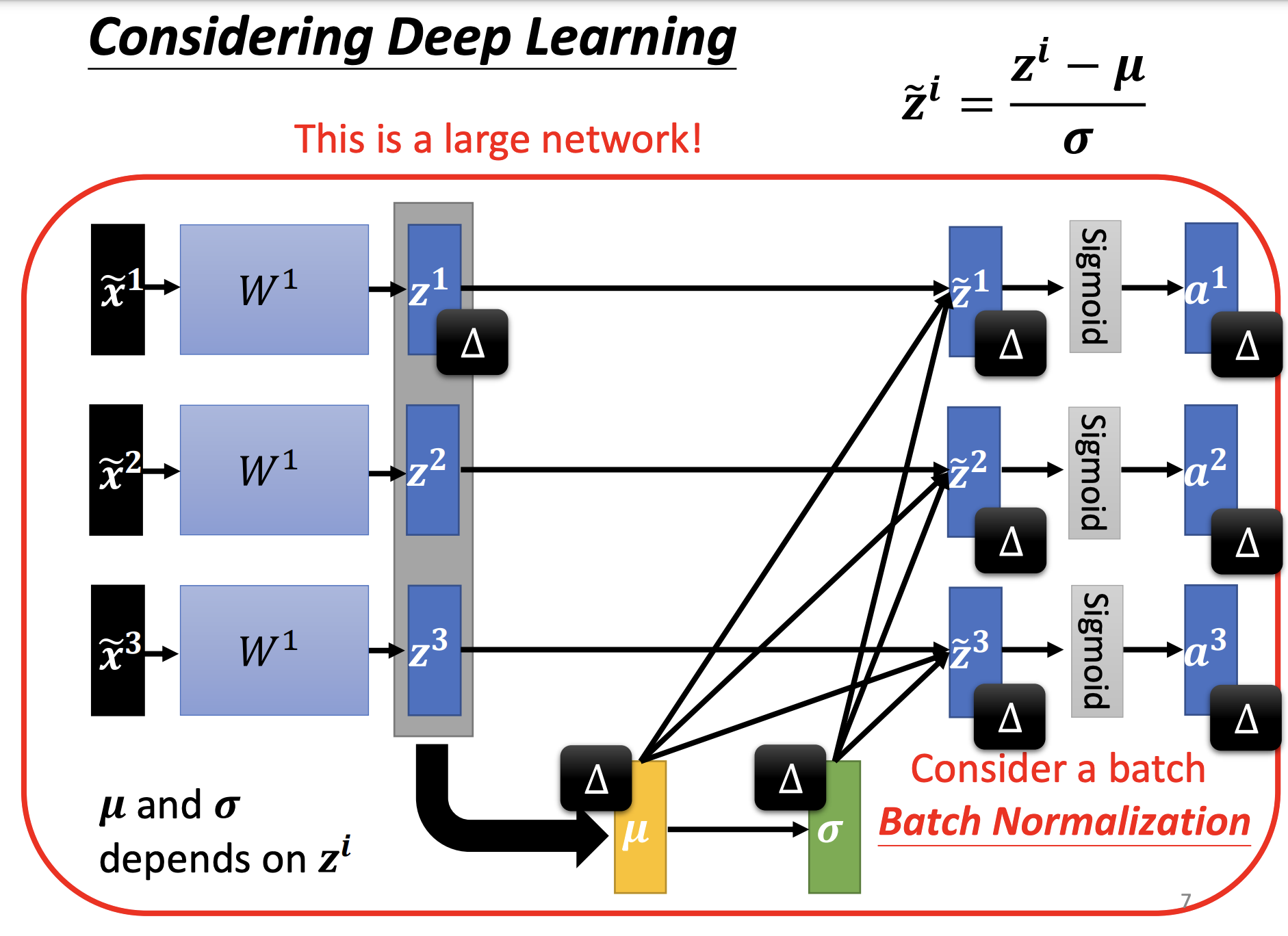
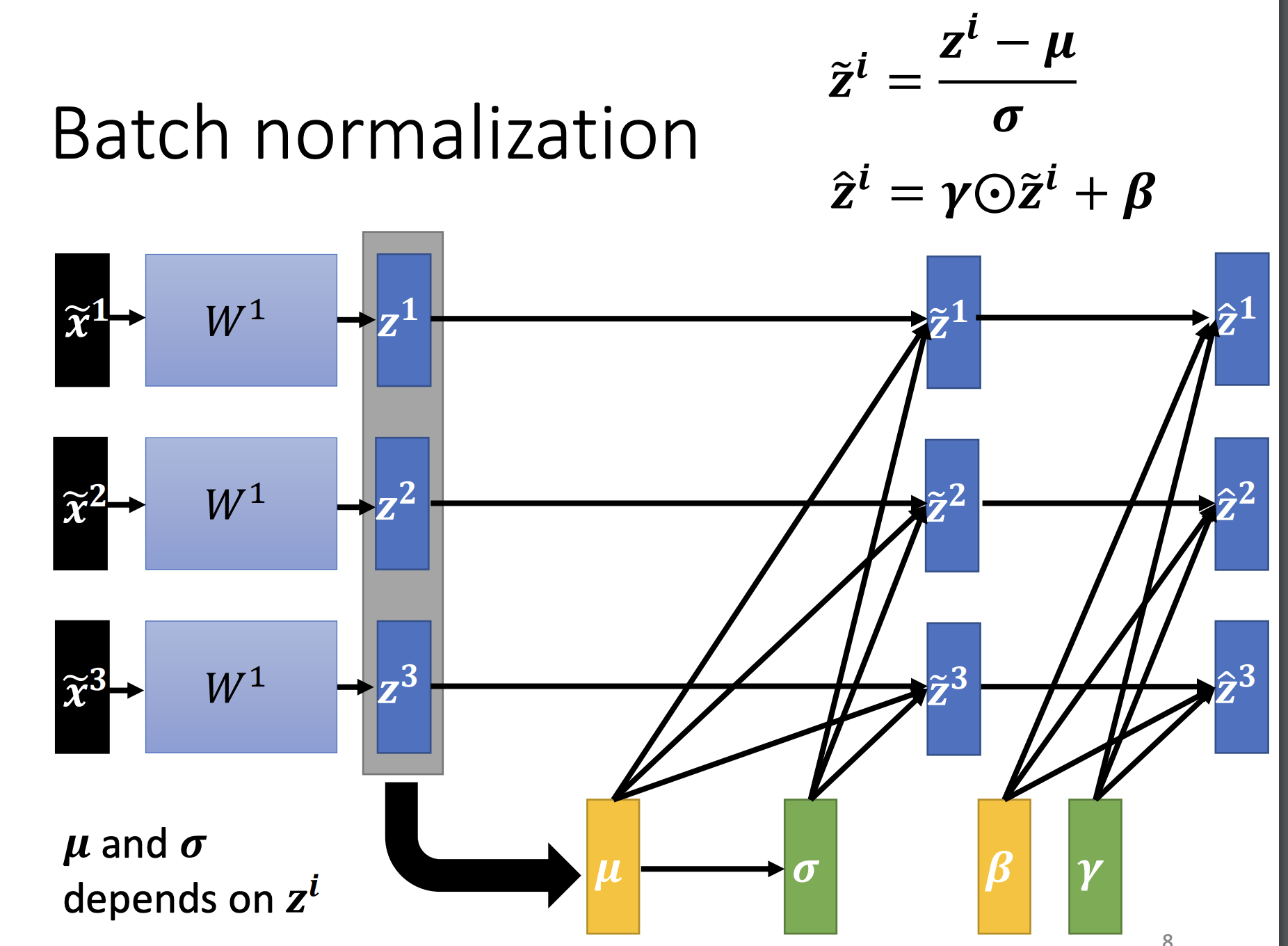
Feature Normalization