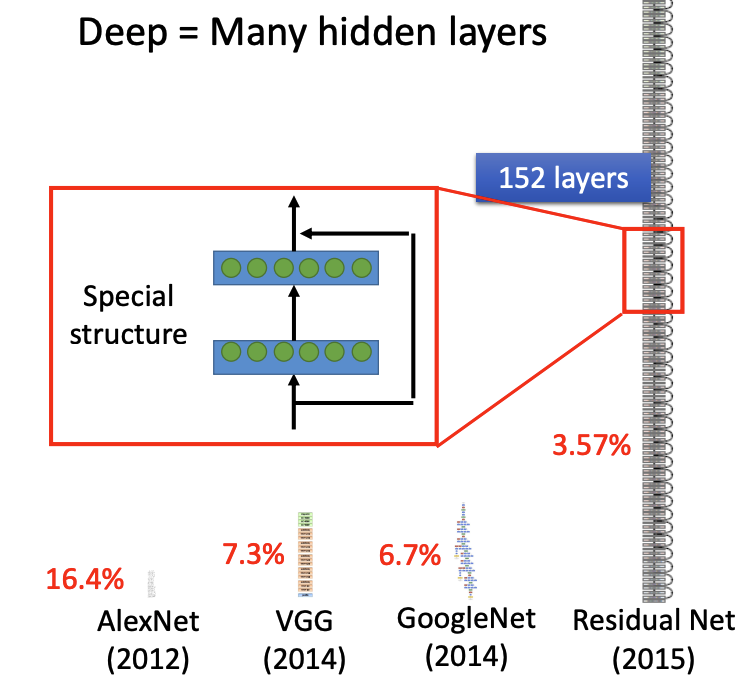
History
- 1958: Perceptron (linear model)
- 1959: Perceptron has limitation
- 1980: Multi-layer perceptron
- Do not have sinificant difference from DNN today.
- 1986: Backpropagation
- Usually more than 3 hidden layers is not helpful
- 1989: 1 hidden layer is “good enough”, why deep?
- 2006: RBM initialization (breakthrough)
- 2009: GPU
- 2011: Start to be popular in speech recognition
- win ILSVRC image competition
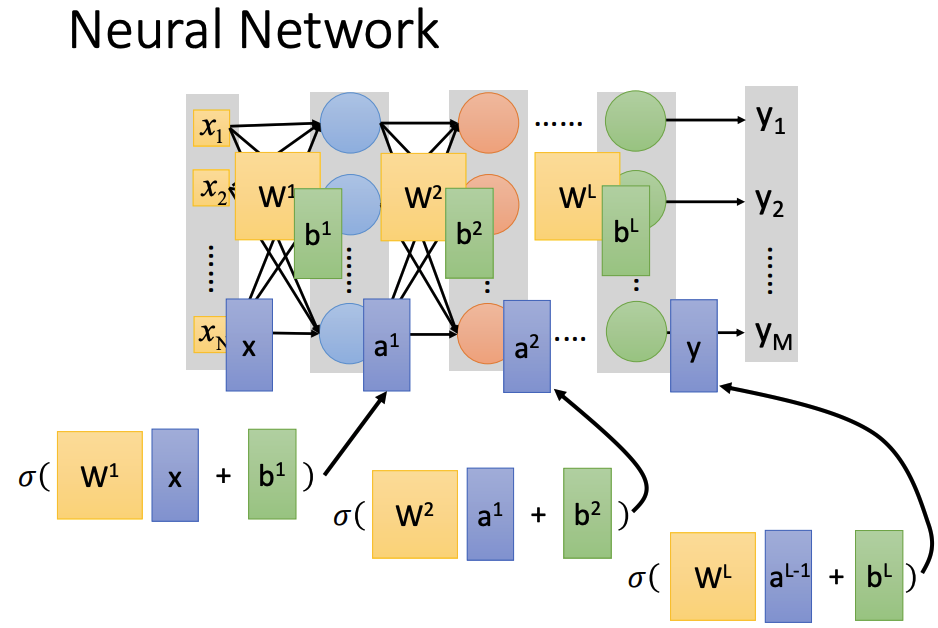
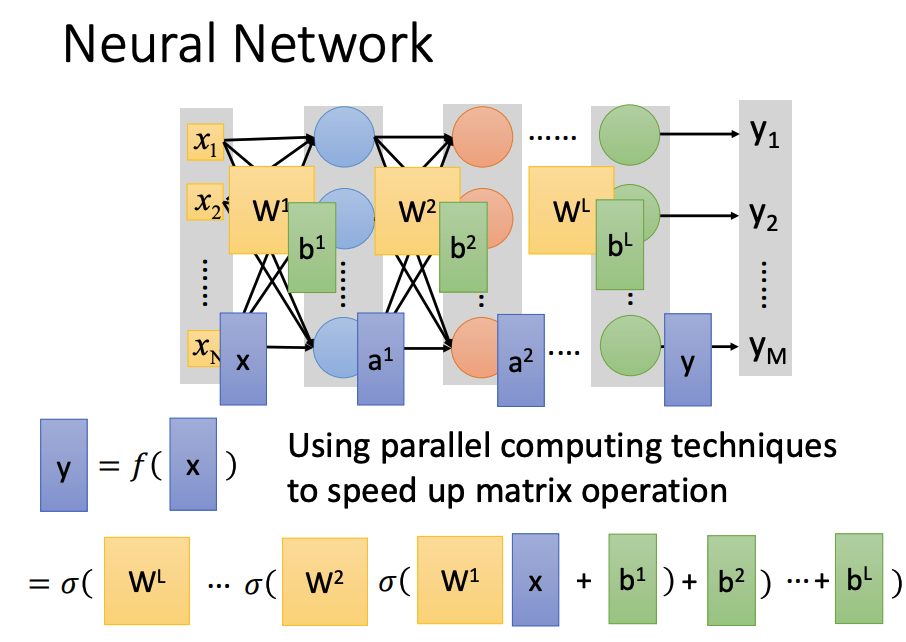
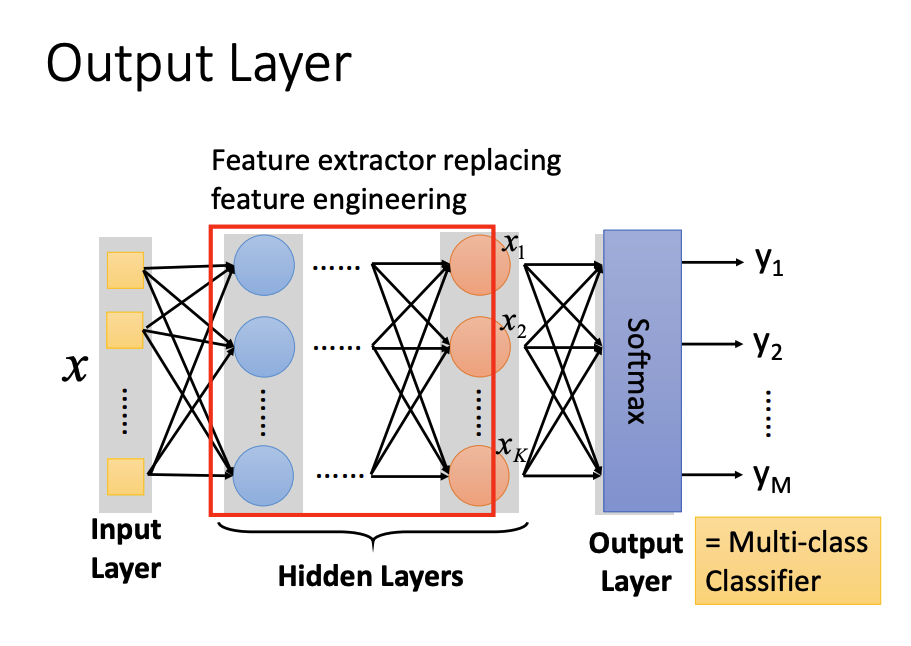
Fully Connect Feedforward Network